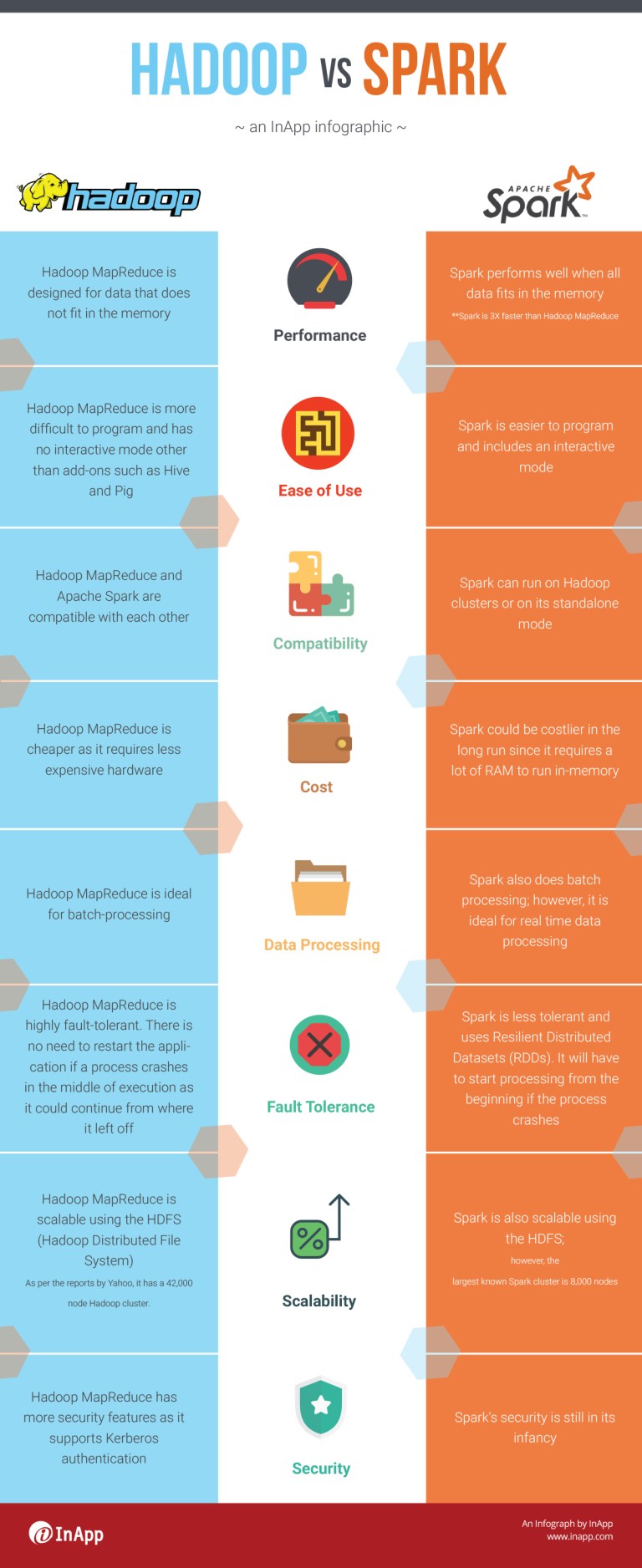
Most often in a conversation about big data, we hear a comparison between Apache Hadoop and Apache Spark. Both are big data frameworks; however, not really serve the same purpose.
Where Hadoop consists of whole components including data processing and distributed file system, Spark is a data processing tool that operates on distributed data collections.
Let’s take a look at what they do and how they differ.
Hadoop is a framework designed to work with huge amounts of data sets across computer clusters using the MapReduce programming model.
Spark is an open-source cluster computing framework generally used for large-scale data processing.
Apache Spark and Apache Hadoop have a synergetic relationship with each other. The speed, agility, and relative ease of use of Spark complement the low cost of operation of Hadoop. Hadoop is the best choice for businesses that need huge datasets with batch processing, whereas Spark is ideal for applications that require fast and iterative processing.