Data pipelines are a crucial component of any big data solution. These are software that handles data streaming and batch processing, whereby data undergoes various transformations along the way.
This blog describes various big data streaming/batch processing options available with private clusters leveraging open-source technologies and serverless public cloud infrastructures like AWS.
Option 1: Serverless Architecture with Kinesis, Lambda & DynamoDB
The biggest advantage of the serverless architecture is that the services run on a managed infrastructure from the provider (for this instance, let’s take AWS).
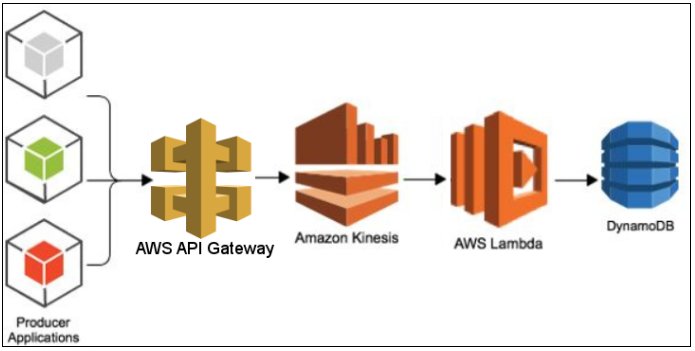
The above diagram focuses on AWS-managed services listed below:
API Gateway – Provides end-point for client on-premise installations to push data.
Kinesis – A streaming solution that is capable of storing data in shards for a certain retention period. Each shard can store at the rate of 1000 records per second, with a maximum size of each record limited to 1 MB.
Lambda – Listeners that are capable of being triggered when data arrives in Kinesis. Kinesis will buffer the number of records until a batch size is reached or a window expires. For scalability, the number of shards needs to be increased as the number of Lambda processors.
DynamoDB – The NoSQL database for receiving the raw data. It is a highly scalable storage option, where data is stored in shards based on the read and write capacity. One consideration here is the maximum limit of reading (40000 for certain regions) and write capacity (40000 for certain regions), which, of course, can be increased through request. A max of 40000 indicates 40000 * 4KB * 2 = 320 MB/sec per table. In reality, a read capacity of 4000 is common. A single table on NoSQL would be designed to host multiple entities due to its schema-less nature. The partition key chosen should be so dense that the data would be uniformly distributed, and there won’t be any “Hot” partitions as a result of a sparse key.
Option 2: Open Source Data Pipeline with Kafka
This architecture involves a Kafka-only solution where the Kafka REST proxy is used as the REST end-point to which client deployments would send data. This data would get stored in the Kafka partitions. Kafka-connect could be configured to siphon the data to a distributed file storage like HDFS or an RDBMS like PostgreSQL or a NoSQL database like MongoDB in a batch process. As for stream processing, Kafka consumer programs could process the data by performing aggregations and other calculations generating new streams or updating external databases.
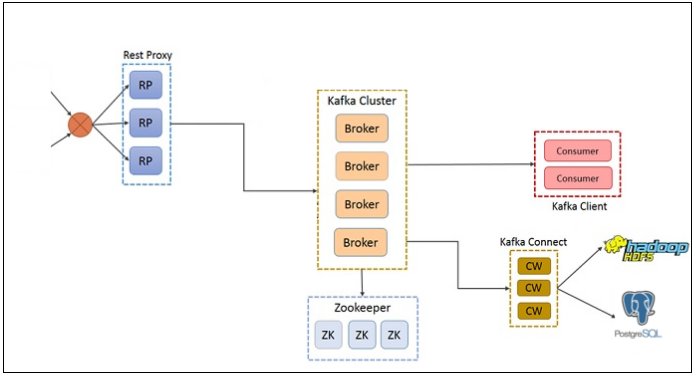
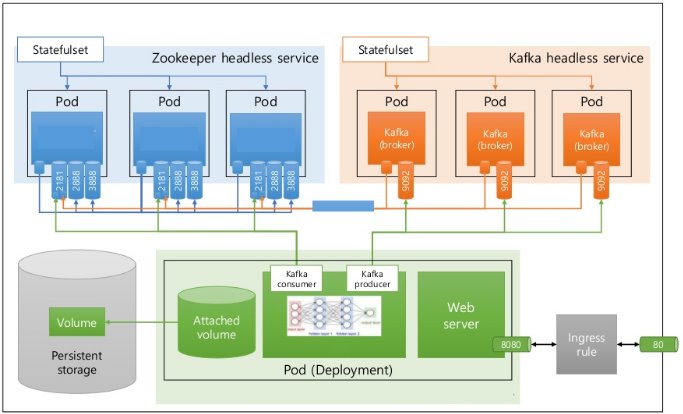
A Kafka cluster serving the data pipeline could be easily set up inside a Kubernetes cluster. Kafka consumers would consume the ingested data and produce new topics across multiple partitions. Data from these partitions could be visualized through a web server.
Option 3: Open Source Data Pipeline with Kafka and Spark
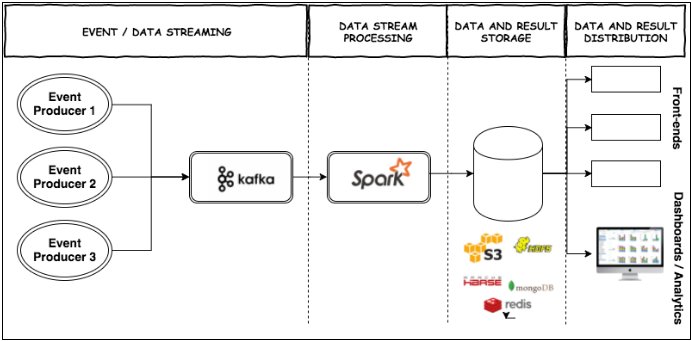
In this solution, we use Kafka as the streaming engine that ingests the data from an external source and Spark as the batch processor, storing the data as a distributed dataset in HDFS or NoSQL databases like MongoDB / Redis. The Spark job would start reading data from a particular beginning offset in Kafka up to an end offset, remembering both offsets to repeat the process for subsequent iterations.
A separate pipeline could be used to stream the Kafka data to perform aggregations and push the resulting data into an RDBMS or NoSQL database.
Option 4: Serverless Architecture with Kinesis and AMR
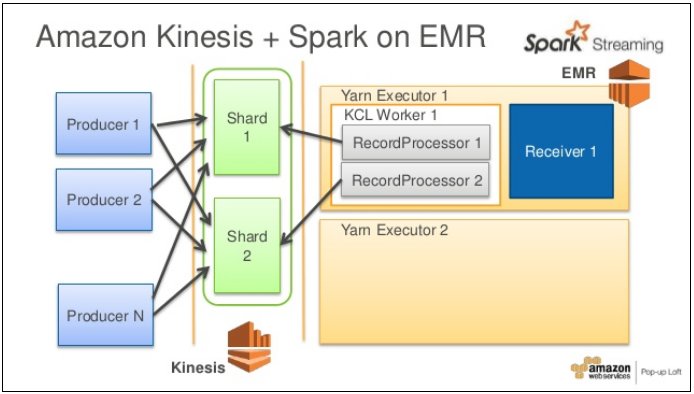
In this architecture, we pump data into Kinesis and have EMR Spark-based consumer programs using the Kinesis Client Library to pick up data from Kinesis. The KCL uses a unique Amazon DynamoDB table to keep track of the application’s state called “checkpointing” to recover if a processor crash happens. A newly started processor would look for the last read UUID and start off reading messages so that no message is lost. Of course, we need to set the read and write capacity of the DynamoDB such that checkpointing does not suffer. Overall, we should make necessary adjustments so that there are no bottlenecks either at the sender, the Kinesis, the processor, or the storage end.
Conclusion
Irrespective of the data pipeline we choose, it’s necessary that the design be capable of handling bottlenecks from all fronts of the architecture.
The Kinesis Producer Library (KPL) could efficiently put records into Kinesis on the sender side. A Kinesis agent that wraps the KPL is also available that supports retries, aggregations, failover, and such.
On the streamer side, Kinesis Data Stream provides real-time streaming capability. Of course, the number of shards is a key configuration attribute that would depend on the throughput. We can use Cloud watch metrics to monitor throughput exceptions and then decide if we need to increase the number of shards. We can also program the system in such a way as to increase and decrease the number of shards based on CloudWatch metrics.
On the processing side, we could use the KCL with checkpointing capabilities so that in case of a processor crash, it automatically spawns another process that would start from where the previous processor discontinued.
